- Saboya Yang
yangsaboya@pku.edu.cn - Jiaying Liu
liujiaying@pku.edu.cn - Wenhan Yang
yangwenhan@pku.edu.cn - Zongming Guo
guozongming@pku.edu.cn
Published on APSIPA, December 2014.
Introduction
Image sparse representation refers that a patch can be approximately expressed as a linear combination of few prespecified atom patches. And the sparsity constraint is that few of linear coefficients are nonzeros. While each atom patch refers to a dictionary base, all atom patches combine to be an over-complete dictionary. Yang et al. [1] introduced sparse representation into super resolution (SR) to obtain high resolution (HR) image, named ScSR. He exploited linear programming to solve the sparse representation of low resolution (LR) patches. It is easy to understand and operate, which attracts much attention. However, ScSR extracts samples from arbitrary regions to train the dictionary. When reconstructing one specific object, the dictionary which represents individual structural characteristics is needed. Nowadays, many researchers focus on training a dictionary with general representativeness and containing different kinds of image structural properties [2]. Nonetheless, the sparse decomposition based on the over-complete dictionary is unstable for complex natural images and may produce some artifacts. This means when exploiting general dictionary, it is hard to reconstruct local features adaptively. Therefore, there is still much work to be done to acquire more adaptive dictionaries.
From the view of biological vision, when looking at one image, people usually focus on salient and edge regions. And from another view of the scientific analysis, human eyes are especially sensitive to structural information. Generally, salient regions and edge regions tend to be highly structured. Taking this property into consideration, salient and edge regions can be extracted to train specific dictionaries. And if these dictionaries are used to reconstruct corresponding regions, more details can be captured. Guided by this intuition, saliency and edge information of images is drawn into the framework to enhance the adaptivity of dictionary.
Implementation
Taking the highly structured property of salient regions and edges into consideration, we propose a SR algorithm using saliency and edge information based on sparse representation. The framework of the proposed algorithm is illustrated in Fig.1.
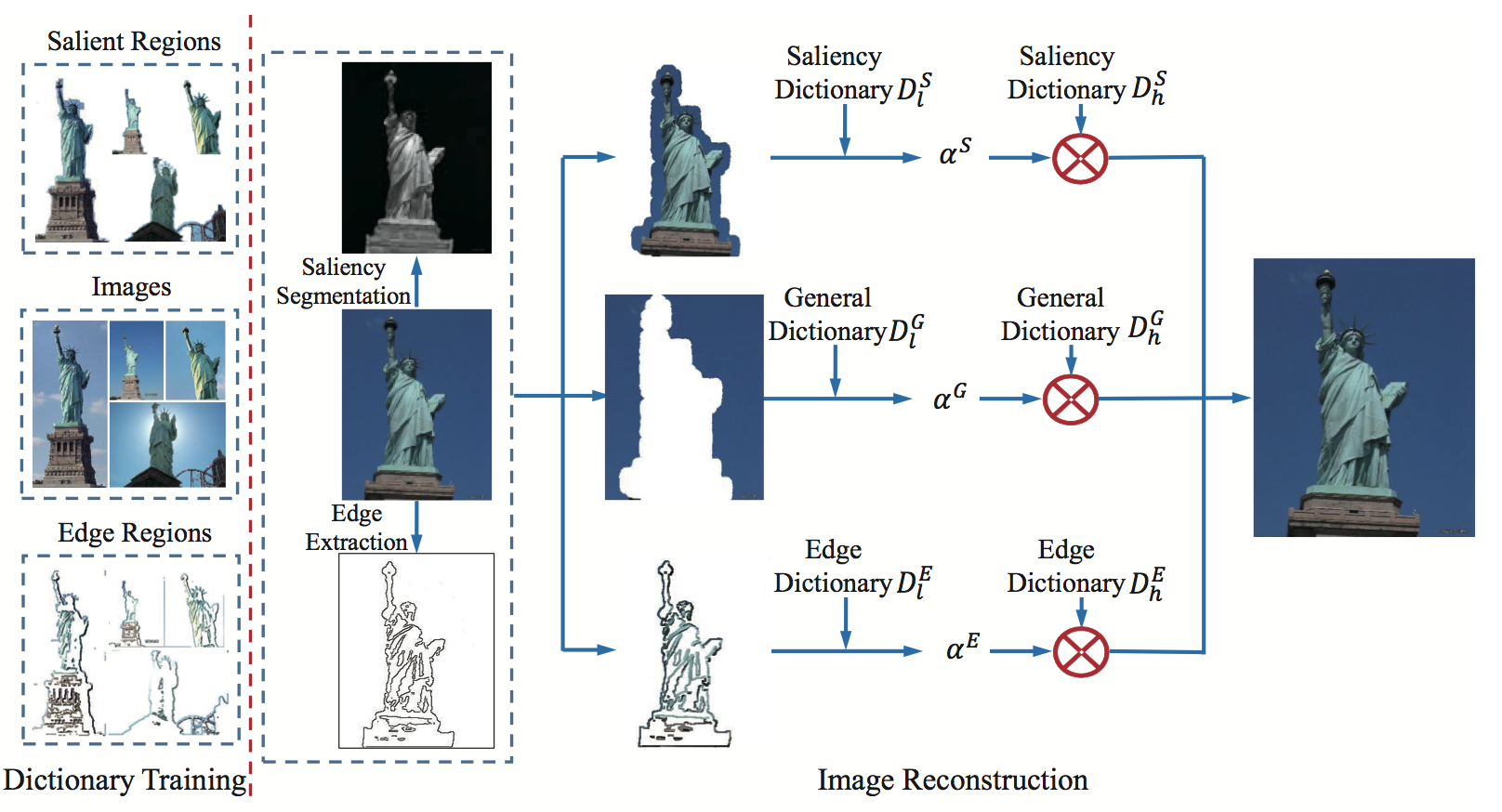
Fig.1 The Framework of the Sparse Representation Based Super Resolution Using Saliency and Edge Information Algorithm.
Saliency Dictionary Learning
Inspired by [3], salient regions are segmented using the contrast filter. To filtrate and obtain regions with larger contrast, the distance between the average feature vectors of the pixels in the subregion and in the neighborhood is measured in CIELab color space. The saliency map shown in Fig.2(b) is acquired after calculating under different scales. And every pixel value in the saliency map equals the saliency value of this pixel. Afterwards, the map is over-segmented by K-means. Then many pixels are gathered together as indicated in Fig.2(c). After calculating average saliency value for each region, we define the regions with average saliency value higher than the threshold as salient regions. Finally, the segmentation result in Fig.2(d) is generated.

Fig.2 An example of salient region segmentation. (a) Original image, (b) Saliency map, (c) Saliency segmentation, (d) Salient region.
With the segmentation result, only patches in the salient regions are extracted as samples to train the saliency dictionary.
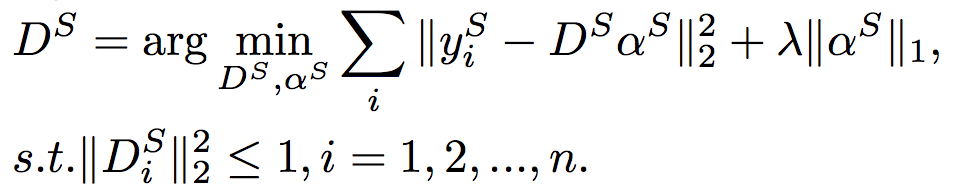
Edge Dictionary Learning
Edges are actually discontinuous regions in which luminance changes rapidly. Ideally, applying edge detection algorithms to the input image results in a group of continuous curves. And these curves clearly show the boundaries of objects, the curved boundaries of the discontinuous surfaces and so on. Hence the edge detection algorithms help get rid of irrelevant information. In this way, the computation cost is reduced and the structural properties of the objects are reserved. As a result, we can extract the edges effectively. In this paper, Canny detector is chosen to extract edges as Fig.3(b). And in Fig.3(c), the edge regions are defined as regions around the edges with the specified width.

Fig.3 An example of edge region extraction. (a) Original image, (b) Edge extraction, (c) Edge region.
After extracting edges, only patches in the edge regions are extracted as samples to train the edge dictionary.
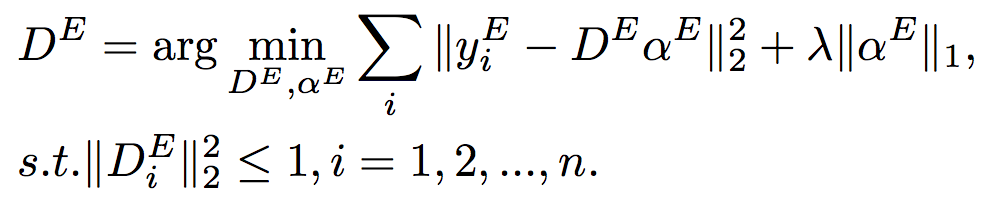
Image Reconstruction Using Saliency and Edge Information
After obtaining the saliency dictionary and the edge dictionary, general dictionary is trained using patches from arbitrary regions. In the proposed algorithm, different regions are reconstructed by different dictionaries. Edge regions utilize the LR edge dictionary to do sparse decomposition and obtain the corresponding edge sparse coefficients. And when multiplying the edge sparse coefficients and the HR edge dictionary, the HR edge regions are obtained. Same as edge regions, salient regions use the LR saliency dictionary and obtain the corresponding saliency sparse coefficients. Then the HR salient regions are obtained after multiplying the HR saliency dictionary. In the meantime, other regions are reconstructed using the corresponding LR general dictionary and HR general dictionary. Finally, the super-resolved image is obtained.
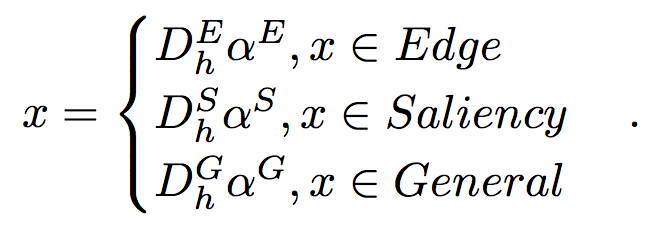
Datasets
The video sequences in this database are intended for research purposes, not for commercial use. And the image sets are extracted from the Internet and generated by downsampling. All images in the same image set are images of the same object taken from different views at different time. The first image in each set is taken as the test image.
1. Colosseum




2. Palace






3. Thai






4. Tower




5. Horse





6. Turret





Experimental Results
In the experiments, we compare the proposed algorithm with the baseline Bicubic method and traditional ScSR[1].
It is shown in the following table that our proposed algorithm performs better than Bicubic and ScSR. Compared with ScSR, our method reduces blocking effects and artifacts along the edges in Fig.4 thanks to the special dictionary. It proves that the salient dictionary and the edge dictionary contribute to obtain adaptive dictionaries and recover more structural information.
| Images | Bicubic | ScSR | Proposed |
| Colosseum | 24.50 | 25.69 | 25.75 |
| Palace | 29.43 | 30.95 | 31.03 |
| Thai | 24.21 | 24.94 | 25.00 |
| Tower | 32.03 | 33.21 | 33.26 |
| Horse | 29.87 | 30.90 | 30.94 |
| Turret | 32.50 | 34.04 | 34.05 |

Fig.4 Subjective comparison of different algorithms on Tower. (a) Original frame, (b) An result of Bicubic , (c) ScSR, (d) Proposed.
Meanwhile, we extend the definition of related images. In one image set, there may exist images about the same kind of object, which means the limitation is not only the same object. In this way, we combine four image sets Colosseum, Palace, Thai and Tower into one Architecture set. After re-training the dictionaries, we obtain the comparison results presented in the following table and Fig.5. According to the results, we realize that the proposed method still improves the performances. This leads to the conclusion that our method has relatively comprehensive adaptability, and it is not limited to the same object.
| Images | Bicubic | ScSR | Proposed |
| Colosseum | 24.50 | 25.69 | 25.75 |
| Palace | 29.43 | 30.95 | 31.07 |
| Thai | 24.21 | 24.94 | 25.04 |
| Tower | 32.03 | 33.21 | 33.34 |

Fig.5 Subjective comparison of different algorithms on Palace. (a) Original frame, (b) An result of Bicubic , (c) ScSR, (d) Proposed.
References
[1] J. Yang, J. Wright, T. Huang, Y. Ma. Image super resolution via sparse representation. IEEE Transactions on Image Processing, Nov 2010, 19(11): 2861-2873.
[2] M. Protter, I. Yavneh, M. Elad. Closed-form mmse estimation for signal denoising under sparse representation modeling over a unitary dictionary. IEEE Transactions on Signal Processing, July 2010, 58(7): 3471-3484.
[3] R. Achanta, F. Estrada, P. Wils, S. Susstrunk. Salient region detection and segmentation. International Conference on Computer Vision Systems, 2008, 66-75.