- Saboya Yang
yangsaboya@gmail.com - Jiaying Liu
liujiaying@pku.edu.cn - Qiaochu Li
lqc_atlas@qq.com - Zongming Guo
guozongming@pku.edu.cn
Published on APSIPA, November 2013.
Introduction
Multi-frame super resolution (SR) methods reconstruct a high resolution (HR) frame from multiple low resolution (LR) frames. They are based on the assumption that LR frames can complement each other by a large amount of redundant information. Motion estimation techniques are employed in SR to obtain redundant information. However, due to the complexity of motion, unavoidable motion estimation error leads to annoying artifacts in super resolved HR frame. To avoid this problem, Potter et al. [1] proposed a motion-estimation-free algorithm based on nonlocal means (NLM). NLM SR takes the advantage of the redundancy of patches existing in images. It obtains a better HR image with no explicit motion estimation by replacing every pixel with a weighted average of its neighborhood.
In the past decade, researchers made progress in NLM SR by improving patch matching and exploiting more information. Some suggest adaptively choosing parameters. And some develop a new way of calculating similarities to use more available information. And our previous work took rotation and illumination into consideration. However, in practical captured videos, global and local scale change frequently appear. While global scale change is caused by camera motion, object motion leads to local scale change.Taking Fig.1 as an example, camera motion and object motion bring different scale changes in different regions. As a result of scale change, it is difficult to find similar patches for NLM, which affects the performance of NLM SR.

Fig.1 Scale changing effects in adjacent frames.
In order to solve the above problem and consider the different scales in different regions, we propose a new method of patch matching to find similar patches for NLM. We segment the frames into several regions based on parameter model. The scale operator based on Scale-Invariant Feature Transform (SIFT) [2] is used to help us to obtain the scale differences and modify all matched patches into the same scale to compute the weights for NLM SR.
Implementation
Taking camera motion and object motion into consideration, we propose a scale-invariant NLM SR algorithm based on segmentation. The framework of the proposed algorithm is illustrated in Fig.2.

Fig.2 The Framework of the Segmentation-Based Scale-Invariant Nonlocal Means Super Resolution Algorithm.
Parameter Model Based Segmentation
First, SIFT is utilized to extract and match feature points from the LR candidate and reference frames. And the affine model, which is used to describe local optical flow in THE candidate frame, is initialized based on the feature information SIFT extracted. To detect boundaries, we reduce the influence of texture by decomposing the frame and we compute NLM mask in structure layer. The following weighted affine model is calculated by the weighted Lucas-Kanade algorithm [3]:
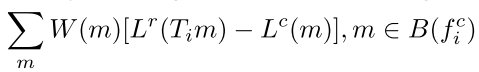
Confidence map is used to extract support regions for each corresponding feature pair. And all pixels in one support region share the same affine parameters so that they share the same scale parameters.
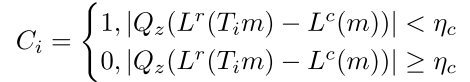
In order to improve the robustness of confidence map and preserve boundaries, Canny detector is used to detect edge points which provide useful information for support region searching. And instead of a pixel, we use a ball to search the field to avoid those gaps between points, proposed as the trapped ball method [4]. Besides, to solve this problem of the fragmentized segmentation result, the methods of hierarchical clustering and morphological dilation are utilized to investigate grouping regions.
Scale-Invariant Patch Translation
Feature information extracted by SIFT is used to do weighted summing for every region in each frame. The average scale difference of all matched points in corresponding regions of two frames is obtained:
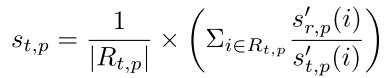
When a corresponding region cannot be related because of the mismatching of feature points, the global scale between two frames is used to represent the scale difference between the corresponding regions of two frames.
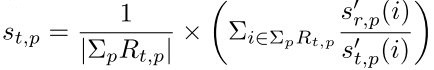
Given those scale differences, corresponding patches in different scales are modified into the same scale by interpolation. In Fig.3, when patch is modified, weights between similar patches are higher (lighter blocks in the figure), which means the proposed method provides more useful information.

Fig.3 Comparison of unmodified and modified patch in patch matching.
To reconstruct the reference frame, we calculate the weighted average of all pixels in the equivalent low resolution neighborhood of pixel in the reference frame.
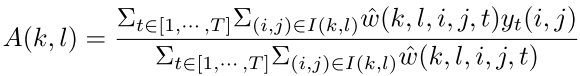
Datasets
The video sequences in this database are intended for research purposes, not for commercial use. And the images are extracted from the video and generated by downsampling. Click the name of the videos to to download.















4. Owl Extracted from the movie "Harry Potter And The Goblet Of Fire", Copyright belongs to the Warner Bros Pictures.










Experimental Results
In the experiments, we compare the proposed algorithm with traditional NLM SR. And to demonstrate the necessity of segmentation, we specially propose an algorithm to reconstruct the frame only considering the global scale of the frame without segmentation, called Scale-Compensated NLM SR (SC NLM).
It is shown in the following table that our proposed algorithm performs better than NLM SR and SC NLM SR. The average gain of our proposed algorithm is 0.678 dB compared with NLM. And on test set Walk, due to the obvious zooming of camera and object motion, scale changes significantly between frames. Our algorithm has a large gain of 1.47 dB. This proves that the segmentation-based scale-invariant NLM SR algorithm we propose extracts more effective information from the sequences. And it is necessary to segment the image so that we take local scale changes into account instead of only considering global scale change.
| Images | NLM [1] | SC NLM | Proposed |
| Walk | 23.51 | 24.00 | 24.98 |
| Girl | 22.84 | 23.21 | 23.45 |
| Man | 24.94 | 25.62 | 25.97 |
| Owl | 28.06 | 28.17 | 28.18 |
| Road | 26.77 | 26.90 | 26.93 |

Fig.4 Subjective comparison of different algorithms on Man. (a) Original frame, (b) An result of NLM SR , (c) SC NLM SR, (d) Segmentation-Based Scale-Invariant NLM.
Subjective results on test set Man in Fig.4 show zoomed comparison of the face and car window part in the original image by different methods. Compared with NLM, Fig.4(d) reduces blocking effects and artifacts along the edges.
References
[1] M. Potter, M. Elad, H. Takeda, and P. Milanfar. Generalizing the Nonlocal-Means to Super-Resolution Reconstruction, IEEE Transactions on Image Processing, vol. 19, no. 1, pp. 36-51, January 2009.
[2] D. G. Lowe. Distinctive Image Features from Scale-Invariant Keypoints, International Journal of Computer Vision, vol. 60, no. 2, pp. 91-110, 2004.
[3] B. D. Lucas and T. Kanade, An iterative image registration technique with an application to stereo vision, Proceedings of Imaging Understanding Workshop, pp. 121-130, 1982.
[4] S. Zhang, T. Chen, Y. Zhang, S. Hu and R. Martin. Vectorizing Cartoon Animations, IEEE Transactions on Visualization and Computer Graphics, vol. 15, no. 4, pp. 618-629, July. 2009.