王选所师生参加 EMNLP 2023
发布时间:2023-12-25
发布时间:2023-12-25
EMNLP 2023(The 2023 Conference on Empirical Methods in Natural Language Processing)于2023年12月6日至10日在新加坡举行。王选所赵东岩老师、研究生张晨、黄曲哲、程信、冯家展、尹训健、胡新宇等多位师生参加了此次会议。
EMNLP由ACL旗下SIGDAT组织,每年举办一次,更加偏向于自然语言算法在不同领域解决方案的学术探讨。EMNLP在Google Scholar计算语言学刊物指标中排名第二,是CCF-B类推荐会议。EMNLP 2023于12月6日~10日在新加坡召开,共收到投稿4909余篇。

王选所部分参会人员合影

王选所部分参会人员合影(左起:胡新宇、尹训健)
王选所万小军组师生在本次会议上共发表6篇文章,包括1篇oral长文和2篇poster,以及3篇findings论文。主会论文具体信息如下:
Hui Liu and Xiaojun Wan. Models See Hallucinations: Evaluating the Factuality in Video Captioning. EMNLP 2023.
该论文对视频字幕的真实性进行了首次人类评估,并注释了两个事实数据集,并发现 56% 的模型生成的句子存在事实错误,这表明这是该领域的一个严重问题,但现有的评估指标与人类事实性注释几乎没有相关性。该论文进一步提出了一种弱监督的、基于模型的事实性度量 FactVC,它在视频字幕的真实性评估方面优于之前的度量。
Xunjian Yin, Baizhou Huang and Xiaojun Wan. ALCUNA: Large Language Models Meet New Knowledge. EMNLP 2023.
该论文旨在解决大模型时代数据泄露的问题,提出了KnowGen的方法,通过修改现有实体的属性和关系,快速生成全新的知识用于测试模型。该论文使用KnowGen方法建立了ALCUNA基准,旨在评估大模型在新知识理解、区分和关联等方面的能力。这项工作的目标是让LLMs更好地应对新知识,对其泛化性进行合理评估。
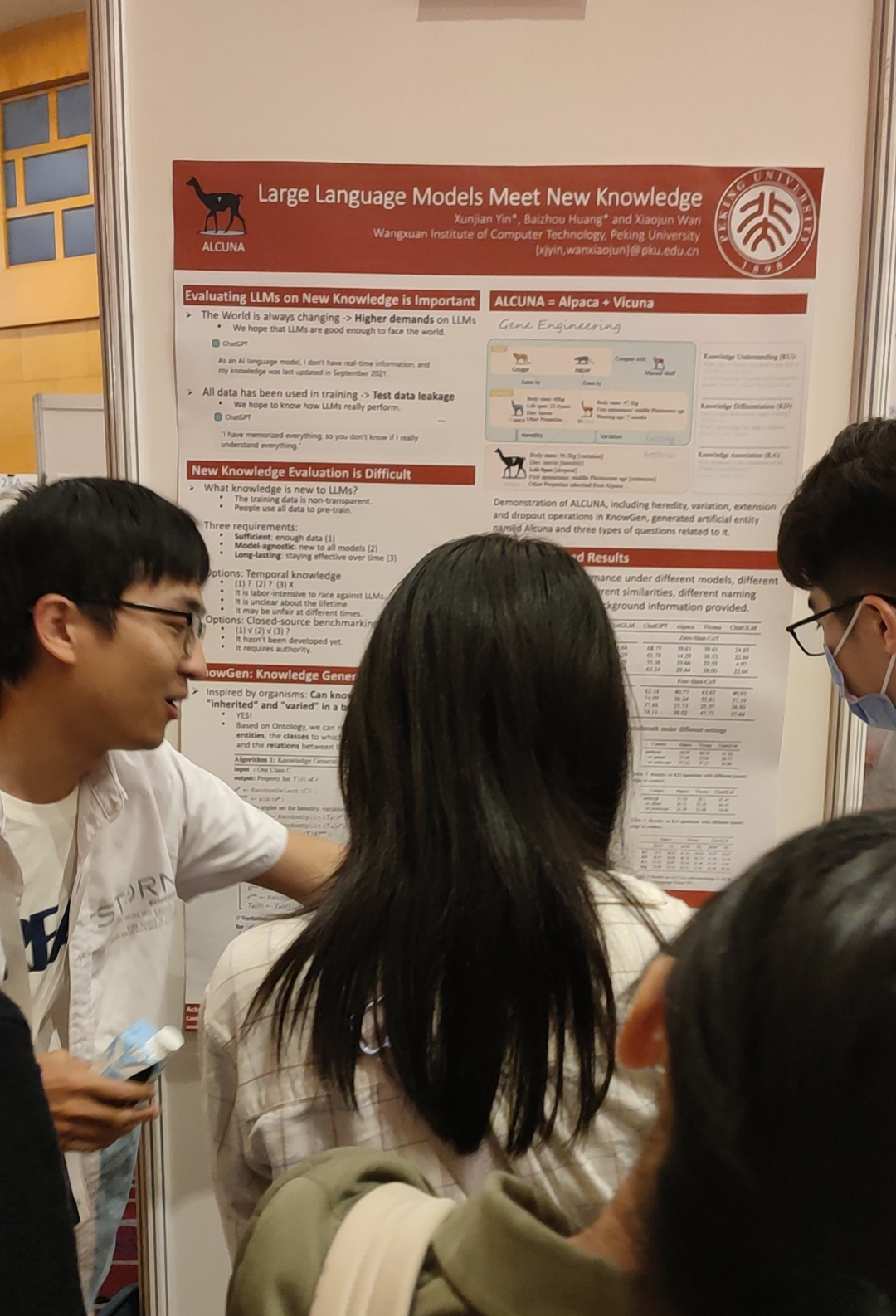
尹训健(左一)做海报展示
Xinyu Hu and Xiaojun Wan. Exploring Discourse Structure in Document-level Machine Translation. EMNLP 2023.
该论文针对文档级机器翻译任务提出了一种更合理的段落翻译模式,并探讨了利用篇章结构信息提升翻译质量的方法。实验表明,基于RST解析树的多粒度注意机制模型取得了较好的整体翻译效果,包括篇章特征的表现。
王选所赵东岩组师生在本次会议上共发表10篇文章,包括2篇主会论文,以及8篇findings论文。主会论文具体信息如下:
Chengang Hu, Xiao Liu, Yansong Feng. DiNeR: A Large Realistic Dataset for Evaluating Compositional Generalization. EMNLP 2023.
本论文致力于探索和解决自然语言理解中的组合泛化问题。研究团队提出了一个名为的任务,旨在通过菜名识别任务来评估模型在理解和生成新的元素组合方面的能力。该任务基于一个大规模、真实的中文菜谱数据集,涉及多种语言现象,如省略、歧义等,增加了数据集的多样性。研究中提出了两种基线方法:基于的持续预训练和组合提示的微调,以及基于的上下文学习方法。这项工作的目标是提供一个基于真实文本的基准,以评估模型在组合泛化方面的能力。
Zirui Wu, Nan Hu and Yansong Feng. Enhancing Structured Evidence Extraction for Fact Verification. EMNLP 2023
本工作考虑使用非结构化的文本和结构化的表格作为知识库进行事实验证的场景。本工作提出了一种简单而有效的方法,通过利用表格的行和列语义来增强结构化证据的提取。提出的方法包括两个组件:粗粒度表格提取模块和细粒度证据图。实验结果表明,该方法可以有效地提取表格并选择单元格,并为事实验证提供更好的证据集。
上一篇 下一篇