王选所王勇涛课题组取得多项智能驾驶技术新进展
发布时间:2026-04-02
发布时间:2026-04-02
当前,新能源汽车成为了我国的支柱产业,而智能驾驶技术是发展新能源汽车产业的关键技术之一。近期,北京大学王选计算机研究所王勇涛课题组与合作者取得了多项智能驾驶技术新进展。
具体地,该团队针对自动驾驶场景感知问题,提出了4D毫米波雷达-环视相机多模态感知模型架构R4Det、开放式目标检测和实例分割算法VL-SAM v2、开放世界占据栅格理解与自动标注算法AutoOcc、面向开放世界的驾驶场景感知评测基准以及开放式3D目标检测算法OpenAD、检索增强与价值引导的智能驾驶VLA系统KnowVal、面向动态驾驶场景的高质量重建与可控编辑框架DrivingGaussian++。上述成果被人工智能领域顶级国际会议ICCV 2025、NeurIPS 2025、CVPR 2026和顶级国际期刊TPAMI(IF=18.6)发表/录用,同时申请了多项发明专利。
进展1:4D毫米波雷达-环视相机多模态感知模型架构R4Det (CVPR 2026)
为了提升智能驾驶系统的安全性和鲁棒性,智能驾驶车辆通常采用多种模态的传感器获取场景信息进行感知,如环视相机、激光雷达、毫米波雷达等。其中4D毫米波雷达-环视相机多模态组合感知方案具有优秀的感知能力和较高的性价比,受到了包括新能源汽车国际巨头特斯拉公司等车厂的青睐。但是,由于4D毫米波雷达和环视相机模态间的巨大差异,如何融合这两种模态信息高精度且鲁棒地完成智能驾驶感知任务(如3D目标检测)具有非常大的技术挑战性。
针对该技术难题,王勇涛课题组与合作者提出了基于4D毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测方法R4Det。具体地,针对绝对深度估计模块精度有限的问题,提出了一种全景深度融合模块,摒弃了稀疏的度量回归,引入序数排序损失;针对缺乏自车位姿时的时序融合问题,提出可变形门控时序融合模块,以对齐非刚性运动;针对小体积物体(例如远处的行人和骑行者)召回率和准确率低的问题,提出了一种实例引导的动态优化模块。实验证明,该方法可以即插即用于现有的多模态3D目标检测模型架构,并大幅提升其检测精度。
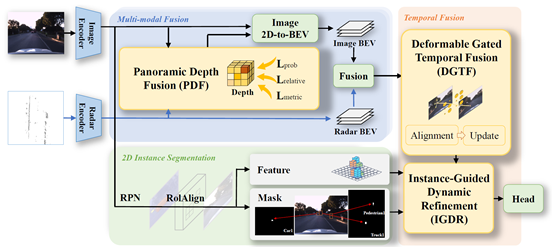
图1 R4Det架构图
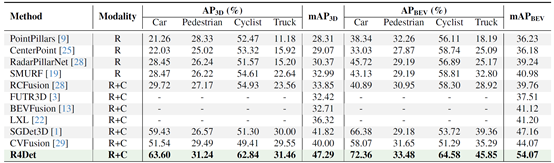
表1 R4Det在TJ4DRadSet上的3D目标检测精度对比

表2 R4Det在VoD上的3D目标检测精度对比
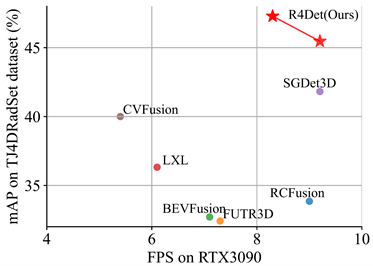
图2 推理速度-精度综合性能对比
进展2:开放式目标检测和实例分割算法VL-SAM v2 (NeurIPS 2025)
深度学习在计算机视觉任务方面取得了显著成功,使得目标检测和分割任务获得了重大突破。传统的目标检测方法通常采用闭集(close-set)范式,该范式训练的检测模型仅限于识别和定位训练集中的固定类别,因此存在明显的缺陷,当面对新物体或未见物体时,此类范式可能会对物体进行错误分类或无法检测,从而导致事故。面对开放场景,研究者们提出了开集式(open-set/open-vocabulary)方法,用以识别自然语言提示词相关的实例。但是在智能驾驶等应用场景中,不存在实时的用户提示,相比之下,开放式(open-ended)模型可以识别和分类给定图像中的所有对象,而不需要人类提供的预定义类别列表,更适用于智能驾驶、具身机器人、无人机等智能系统。
针对开放式(open-ended)感知问题,王勇涛课题组提出了一种融合开集式与开放式方法优势的开放世界目标检测与分割框架。如下图,该框架在VL-SAM的基础上,保持发现新物体类别能力的同时,通过通专融合对稀有类别和常见类别目标均实现了优越的检测性能。在LVIS验证集上,VL-SAM-V2在整体和稀有类别AP两项指标上均达到最优水平。这充分验证了,通过通专融合的方式,VL-SAM-V2框架既能保留开集模型在常见目标上的高检测精度,又能继承视觉-语言模型对罕见目标的识别优势。
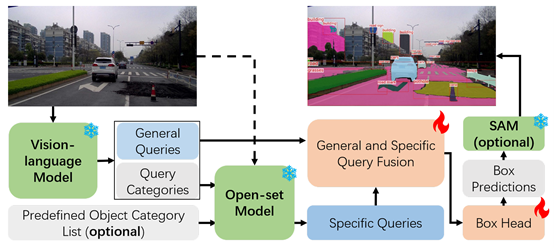
图3 VL-SAM v2算法示意图
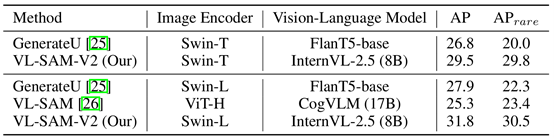
表3 在LVIS上的目标检测精度对比
进展3:开放世界占据栅格理解与自动标注算法AutoOcc (ICCV 2025)
语义3D占据栅格(Occupancy)作为一种融合几何与语义信息的建模方法,逐渐成为复杂场景理解的重要技术。然而,传统的人工标注管线需要高昂的人力和时间成本,并且在极端环境下存在误标注等问题。当前有监督的占据栅格预测方法高度依赖大规模人工标注的数据集与有监督训练机制,不仅成本高昂,且泛化能力有限,严重制约了其在实际场景中的推广与应用。现有自动化与半自动化语义占据栅格真值标注方法普遍依赖LiDAR点云及人工预标注的2D或3D真值。同时,这些方法依赖多阶段后处理,耗时冗长。部分基于自监督的估计方法虽在一定程度上降低了标注依赖,但是难以生成完整且一致的场景语义占据表示,三维一致性难以保障,且缺乏良好的跨场景、跨数据集泛化能力。
为了解决这些关键问题,王勇涛课题组与合作者提出了AutoOcc,一个高效、高质量的Open-ended三维语义占据栅格真值生成框架。AutoOcc基于视觉语言模型和视觉基础模型,从多视图场景重建的视角出发,无需任何人类标注即可超越现有Occupancy标注和预测管线,并展现良好的通用性和泛化能力。
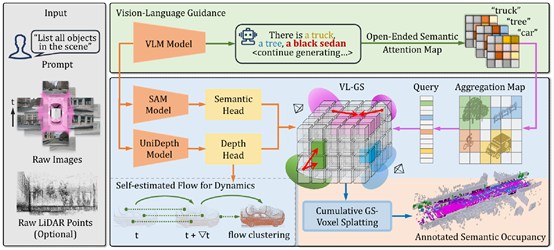
图4 AutoOcc方法示意图
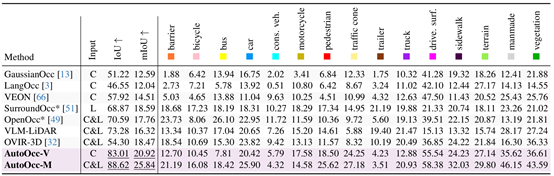
表4 在Occ3D-nuScenes上与现有占据栅格真值标注方法在特定语义类别上进行性能对比

表5 在SemanticKITTI上验证方法在跨数据集与未知类别上的零样本泛化能力
进展4:面向开放世界的驾驶场景感知评测基准以及开放式3D目标检测算法OpenAD (NeurIPS 2025)
前述工作强调了开放式(open-ended)感知与空间理解的重要性,针对这一新兴问题,学术界缺乏相应的评测基准,同时也缺少开放式的3D目标检测方法。因此,王勇涛课题组与合作者开发了一种结合多模态大模型的半自动标注管线,对多个公开数据集进行补充标注,并设计了更适合开放式方法的评测方法。同时,课题组提出了一种以视觉为中心的3D开放世界目标检测基线,并通过通用和专用模型融合,进一步引入了一种集成方法,以解决现有开放世界方法准确率较低的问题。
OpenAD挑战赛长期公开开放(https://github.com/VDIGPKU/OpenAD),欢迎各位目标检测/3D感知/多模态大模型的研究者参与。

图5 OpenAD评测集长尾物体示意图

图6 OpenAD所提出的开集3D目标检测方法架构
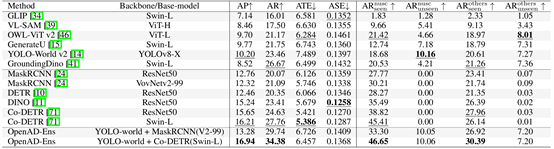
表6 在OpenAD评测集上,对现有闭集、开集和所提出的2D目标检测方法的评测结果
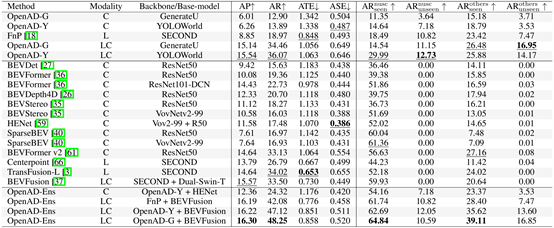
表7 在OpenAD评测集上,对现有闭集、开集和所提出的3D目标检测方法的评测结果
进展5:检索增强与价值引导的智能驾驶VLA系统KnowVal (CVPR 2026)
现有的端到端智驾系统和VLA系统,在走向高阶智能驾驶的过程中,面临着许多问题:一是对规则学习的隐式化,完全依赖数据驱动的隐式规则学习,在面对罕见场景时泛化差,决策可解释性差;二是模态推理的割裂化,VLA模型推理局限于语言层面,无法与感知深度联动,难以处理“视觉场景+语言规则”的复杂推理;三是价值对齐的缺失,仅优化轨迹误差,忽视法律法规、道德原则、防御性驾驶原则与人类偏好。
针对以上问题,王勇涛课题组在多项研究成果的基础上,提出了高阶智能驾驶VLA系统KnowVal。具体地,KnowVal系统通过通专融合的开放世界感知,抽取开放式实例特征,以及全场景占据栅格体素特征,并通过利用轻型 VLM 实现抽象元素理解。接下来,通过感知引导的知识图谱检索,将感知信息进行自然语言化,对包含了法律法规、道德原则、防御性驾驶原则等知识的知识图谱进行检索,得到多条相关性由高到低排列的知识条目以及其特征词元。最后,通过规划模块、隐式世界模型模块和价值模型,进行价值评估,最终选定规划轨迹。该系统的各个模块之间保持了显式结果和隐式特征的共同传递,是可端到端微调的 3D视觉-语言-动作框架。
该系统兼容现有的端到端智驾方法和VLA方法,团队将 KnowVal 框架应用至 GenAD、HENet++、SimLingo、DiffusionDrive、iPad五个基线模型,并在 nuScenes、NAVSIM、 Bench2Drive 三个驾驶基准上进行了测试,取得了领先的结果。

图7 KnowVal算法系统流程
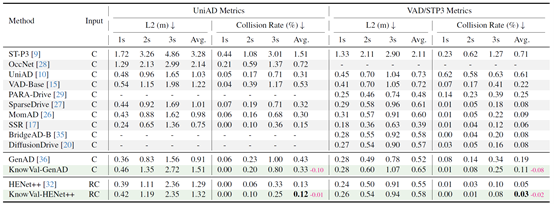
表8 KnowVal在nuScenes基准测试的结果
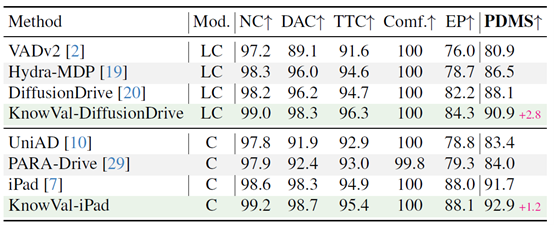
表9 KnowVal在NAVSIM基准测试的结果
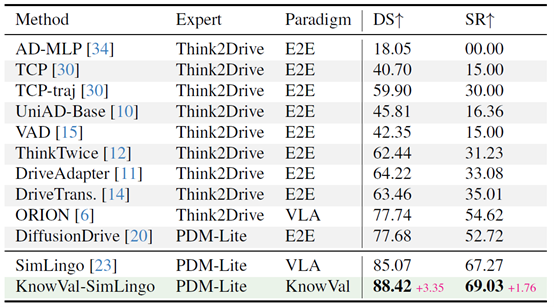
表10 KnowVal在Bench2Drive基准测试的结果
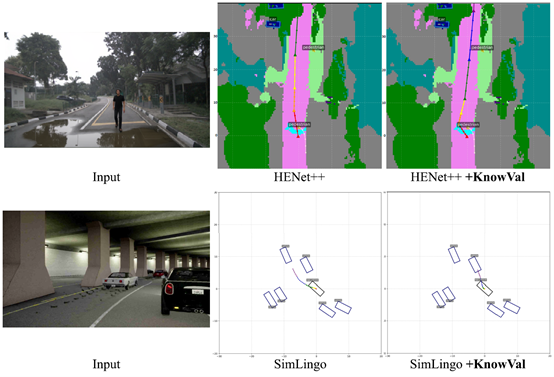
图8 对KnowVal的定性分析
前者测试智能驾驶系统是否能够在路过积水时减速慢行、以免溅到行人;后者测试智能驾驶系统是否会遵循“隧道内实线车道不能变道”的法律法规。实验结果说明,原本无法正确处理这些情况的端到端智驾模型,增加了KnowVal的知识检索与价值评估后,能够正确应对这些情形。
进展6:面向动态驾驶场景的高质量重建与可控编辑框架DrivingGaussian++ (TPAMI 2026)
随着自动驾驶技术的发展,高质量、多样化的驾驶场景数据成为系统测试与验证的关键。3D场景重建与编辑是增强自动驾驶数据的关键,特别是在合成复杂和稀有情况时。传统的三维重建方法(如 NeRF、3DGS)在动态、多视角、大范围的驾驶场景中存在重建精度低、计算成本高、编辑能力弱等问题。尤其是在三维场景数据合成方面,现有方法往往依赖大量训练或专用模型,难以实现高效、一致、可控的编辑。
为了解决这些关键问题,王勇涛课题组与合作者提出了DrivingGaussian++,一个面向大规模动态驾驶场景的高效重建与可编辑仿真框架。DrivingGaussian++通过复合高斯重建将场景分解为静态背景与动态物体,分别进行增量式重建与图结构建模;除此之外,该框架支持三维场景免训练的可控编辑,包括纹理修改、天气模拟和物体操控等多任务,显著提升了三维场景数据合成的真实感与多样性,为自动驾驶仿真提供了一条全新的、高效的数据合成路径。
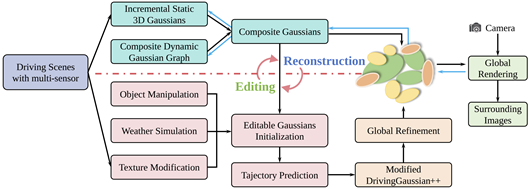
图9 DrivingGaussian++方法示意图
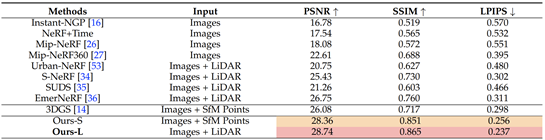
表11 在nuScenes数据集上的重建结果定量对比

图10 编辑结果展示
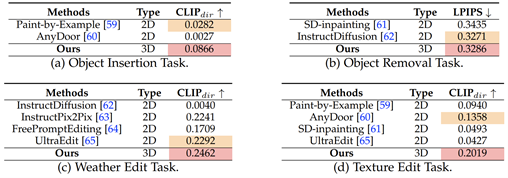
表12 编辑结果定量对比
秉承王选所“顶天立地”的优良传统,近五年来,王勇涛课题组在智能驾驶技术方向进行了不懈的技术研究和应用探索,获得了国家科技创新2030重大项目课题、国家自然科学基金、华为、长安汽车横向科研项目支持经费逾千万元,取得了多项代表性成果,得到了学术界和工业界的广泛关注和好评。
上一篇:北大王选所陈文拯团队在超大规模城市三维重建上取得重要进展 下一篇:王选计算机研究所直属党支部举行“弘扬王选精神,创新赋能未来”主题党日活动