王选所机器智能实验室在基于折反射成像系统的三维人体姿态估计等研究中取得进展
发布时间:2021-08-30
发布时间:2021-08-30
人工智能领域顶级会议IJCAI (International Joint Conference on Artificial Intelligence)于2021年8月21-26日召开。王选所穆亚东老师负责的机器智能实验室在本年度IJCAI会议发表3篇长文[1-3]。其中,在题为“Learning 3-D Human Pose Estimation from Catadioptric Videos”的论文中,提出了一种新颖的基于折反射(catadioptric)成像系统的三维人体姿态估计(3-D human pose estimation)技术。论文主要内容由该实验室博士生刘臣臣、硕士生李勇志、包培钧等人合作完成。
三维人体姿态估计是计算机视觉领域的经典任务,旨在从视觉信号中精确估算人体关节点的三维坐标。现有相关技术多采用在人体关节点绑定空间位置感知传感器、或者从多个视角同时采集人体视觉影像等手段来获取关节点的三维坐标。这些方法由于对于定制化硬件或采集环境的严重依赖,通常只用于训练数据的采集或小规模场景的计算。
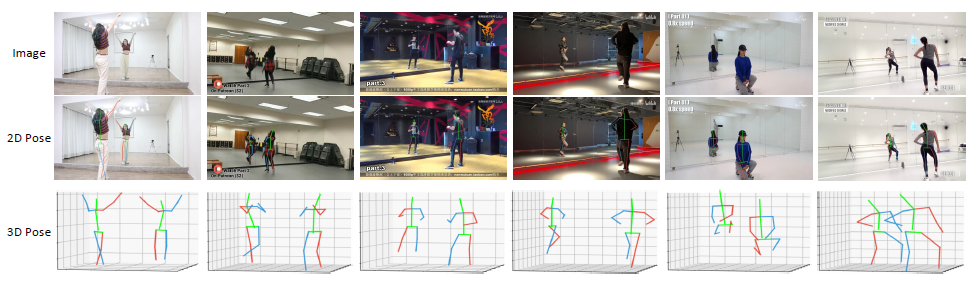
图1:基于折反射成像系统的三维人体姿态估计(文献[1])示意图。
针对这一问题,机器智能实验室首次提出了一种基于折反射成像系统(如图1中所示的健身或舞蹈场景中的立镜和相机共同组成的系统)的技术。传统的基于极限几何(epipolar geometry)的三维视觉重建技术需要场景中存在至少两面镜子,才可以求解相机的内外参数和物体关键点位置信息。本文提出引入机器学习和人体骨架先验(如对称性)来消除极线几何计算中的不确定性,能够对相机参数进行近似求解,并推断不可见的人体关节点的三维位置。在场景中只存在单面立镜的情况下,仍然取得极高的人体姿态估计精度。相关技术在智能健身等场景中具有广阔的应用价值,已经申报发明专利。该文构建了当前最大的三维人体姿态估计的数据集DBM。相关代码和数据即将开源。
参考文献(*为通讯作者):
[1] Chenchen Liu, Yongzhi Li, Kangqi Ma, Duo Zhang, Peijun Bao, Yadong Mu*, Learning 3-D Human Pose Estimation from Catadioptric Videos, The 30th International Joint Conference on Artificial Intelligence (IJCAI) 2021.
[2] Xinzhe Zhou, Wenhao Jiang, Sheng Qi, Yadong Mu*, Multi-Target Invisibly Trojaned Networks for Visual Recognition and Detection, The 30th International Joint Conference on Artificial Intelligence (IJCAI) 2021.
[3] Guoqiang Gong, Liangfeng Zheng, Wenhao Jiang, Yadong Mu*, Self-Supervised Video Action Localization with Adversarial Temporal Transforms, The 30th International Joint Conference on Artificial Intelligence (IJCAI) 2021.
上一篇 下一篇